Research
There is an emerging body of software engineering research (e.g. [1, 2, 8] that argues for the benefits of including grey literature in research: for example, that grey literature helps bridge the gap between practice and research, promotes the voice of the practitioner, and helps to better incorporate context. There are also concerns about the use of grey literature in research; for example, concerns about the ability to quality-assure content that is more likely to be subjective and therefore bias. There may also be misconceptions around the status of grey literature, for example whether a grey literature review (GLR) is treating grey literature with the same evidential value as the primary studies of a Systematic Literature Review (SLR).
We are interested in a particular subset of grey literature, a subset we refer to as blog-like content. Some researchers (e.g. [5, 4, 3]) in software engineering have used blog-like content in their research. We use the term blog-like content because blogs and blog posts are good examples of the kinds of content we are interested in, however we do not intend to restrict our work only to blogs and blog posts. Being a subset of grey literature, we are aware that blog-like content inherits both the benefits and challenges of grey literature, for example that blog posts help incorporate the practitioner voice into research, that there are challenges with the quality-assurance of blog posts, and that there may be misconceptions that blog posts are being treated with the same evidential value as primary studies. Blog-like content may come with its own, additional benefits and challenges, for example the benefit of aggregating and triangulating the views of a particular blogger from multiple blog posts; and the challenges of using reader feedback to assess quality.
Aims of the research programme
We have established a long-term research programme, SERENPA, to look at the opportunities to exploit naturally produced artefacts from practitioners in software engineering research. To scope the resources of the SERENPA programme we focus initially on the use of a particular kind of natural evidence: blog-like documents and their content.
Objectives and Research Questions for the research programme
Objectives
This SERENE programme has the following objectives:
- To review and identify the prospective benefits of using naturally occurring evidence (and blog-like documents and content) in software engineering research.
- To review software engineering research conducted to-date that uses naturally occurring evidence (blog-like documents and content).
- To review and identify the prospective challenges of using naturally produced artefacts (and blog-like documents and content) in software engineering research.
- To describe resources (definitions, data and process models, criteria, heuristics, and methodology) for dealing with the challenges.
- To position naturally occurring evidence within a broader ‘framework’ of evidence, and to position blog-like content (and grey literature) appropriately within that framework.
- To clarify the relationship of types of study (e.g. primary, secondary and tertiary studies) and types of evidence (e.g. grey literature, including blog-like content).
- To summarise our empirical investigations into the use of naturally occurring evidence (and blog-like documents and content).
- To describe software tools we have developed to help deal with the challenges.
- To evaluate the resources and software tools.
- To reflect on the limitations of our work, the implications of our work, and future directions for research in this area.
Research questions
Given the current scope of the SERENE programme, we ask the following motivating research question:
How can researchers’ more effectively and efficiently search for and then select the higher-quality blog-like content relevant to their research?
Our question is motivated by the prospective benefits of using blog-like content in software engineering research. To evaluate those benefits (to determine whether they are actual benefits) the research community needs answers to the main research question we have proposed: theoretical, empirical and methodological answers.
There are a number of significant terms within the main research question, and we use those terms to formulate contributory research questions. The contributory research questions are prioritised below, together with a brief indication of the ‘answers’ we develop:
- What inherent difficulties with blog-like content may challenge, undermine, or otherwise hinder our investigation of the main research question?
- What do we mean by the term blog-like content?
- We need to define blog-like content in a way that helps the researcher distinguish such content from other kinds of grey literature, so that the researcher can evaluate the specific contribution of blog-like content.
- How do we define and measure quality?
- We need to develop a set of credibility criteria, and measures for those criteria, to assess the quality of blog-like content in a way that satisfies the standards of research.
- How do we (then) determine the higher-quality blog-like content?
- We need to determine some mechanisms (e.g. thresholds, rules) that the researcher can use to determine the higher-quality blog-like content relevant to the researcher.
- How do we determine relevance?
- We use the term relevance in the sense of topic e.g. that the blog-like article is about software testing, or web application development, or high performance teams.
- How do we define and measure effective and efficient search?
- We develop software tools.
- A related question is: a) How do we ensure the blog-like content searched and selected is representative?
- How do we define and measure effective and efficient selection?
- We develop software tools.
The research ‘stack’ for the current research project
Figure 1 sketches the layers of research being undertaken in the current research project. Already published papers are indicated with italicised acronyms. Papers in preparation, or to be prepared, are indicated with the acronym TBP (to be published). The acronym COAST stands for Credible Online Article Search Tool.
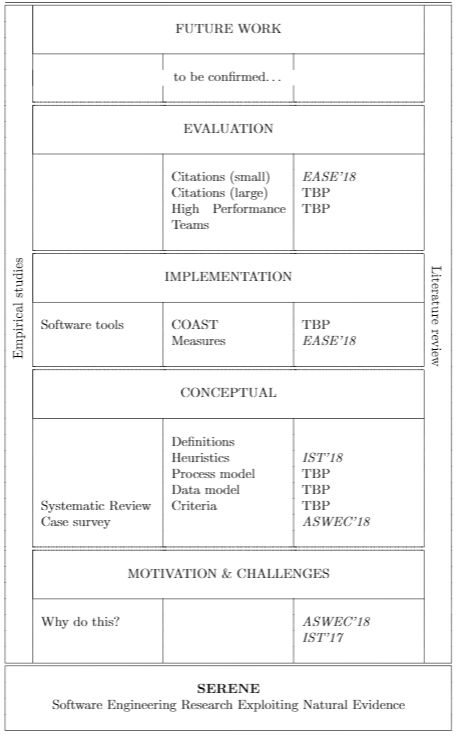
Anticipated contributions of the research programme
Given the current scope of the SERENPA programme, the main contributions of the SERENPA research programme are anticipated to be (in the nearer-term):
- The development of various conceptual resources, such as definitions, data models and process models.
- The review and summary of challenges to the use of blog-like in research.
- The development and evaluation of a set of credibility criteria to be used to assess the quality of blog-like content.
- The development and evaluation of a set of heuristics for search and selection.
- The development and evaluation of software tools to assist with search and selection.
- The development and evaluation of a guidelines and methodology for using blog-like content in research, such as the case-survey methodology for blog-like content [7], and the Arguments, eXplanations and Evidence (AXE) methodology [6].
References
[1] Vahid Garousi, Michael Felderer, and Mika V Mantyla. “Guidelines for including grey literature and conducting multivocal literature reviews in software engineering”. In: Information and Software Technology (2018).
[2] Vahid Garousi, Michael Felderer, and Mika V Mantyla. “The need for multivocal literature reviews in software engineering: complementing systematic literature reviews with grey literature”. In: Proceedings of the 20th International Conference on Evaluation and Assessment in Software Engineering. ACM. 2016, p26.
[3] Dennis Pagano and Walid Maalej. “How do developers blog?: an exploratory study”. In: Proceedings of the 8th working conference on Mining software repositories. ACM. 2011, p123–132.
[4] Chris Parnin and Christoph Treude. “Measuring API documentation on the web”. In: Proceedings of the 2nd International workshop on Web 2.0 for software engineering. ACM. 2011, p25–30.
[5] Chris Parnin, Christoph Treude, and Margaret-Anne Storey. “Blogging developer knowledge: Motivations, challenges, and future directions”. In: Program Comprehension (ICPC), 2013 IEEE 21st International Conference on. IEEE. 2013, p211–214.
[6] Austen Rainer. “Using argumentation theory to analyse software practitioners’ defeasible evidence, inference and belief”. In: Information and Software Technology (2017).
[7] Austen Rainer and Ashley Williams. “Using blog articles in software engineering research: benefits, challenges and case-survey method”. In: Proceedings of the 25th Australasian Software Engineering Conference (ASWEC 2018). 2018
[8] Jacopo Soldani, Damian Andrew Tamburri, and Willem-Jan Van Den Heuvel. “The Pains and Gains of Microservices: A Systematic Grey Literature Review”. In: Journal of Systems and Software (2018).